| ||||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||||
| Web 2.0時代の新しいデータベース〜pureXMLの実力 | ||||||||||||||
このようにXMLデータベース(pureXML)は、従来のRDBMSでは苦手だった商品データのようなケースに向いているのです。さらにpureXMLは、Web 2.0型のサービスに対しても非常に高いポテンシャルを持っています。 Tim O'Reillyによって、「Web 2.0」という考え方が打ちだされてから約2年が経ちますが、日本のインターネットサービスの世界も着々と「Web 2.0」へと移行しつつあります。大手のWebサービスプロバイダーがWeb APIと称されるXMLによるデータ提供サービスをスタートさせ、これまでのHTML中心だったサービスをXMLに広げようとしています。 また、RSSを代表されるようにフィードのフォーマットはXMLデータで、ほとんどのブログサービスでRSSフィードが提供されていることを考えると、非常に多くのXMLデータがインターネット上に流通しているといえます。 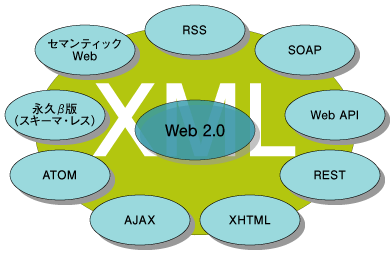 図3:Web 2.0を支えるXML
表4:2007年における代表的なWeb API(XML) このように表面上は、RSSやWeb APIなどXMLデータが当たり前のように流通しているのですが、データベースに関してはどうでしょうか? そうです、いまだにRDBMSを利用しているサービスがほとんどなのです。 そのため、サービスに制限をかけてしまっていると筆者は考えています。例えば、複数の属性を組み合わせて検索するような検索自由度が高いAPIを提供しているWebサイトが少ないことや、繰り返しのある属性に関して指定できる数を限定されてしまうなど、RDBMSの制限に依存してしまうようなWeb APIがまだまだ多いのです。 この「RDBMSの壁」のために、なかなか自由度の高いサービスが提供できていない、というのが現状ではないでしょうか。 仮にpureXMLで格納していたとすると、複数の属性を組み合わせた高速な検索が可能になり、繰り返しのある属性も数を制限することなく持つことができるでしょう(図4、5)。 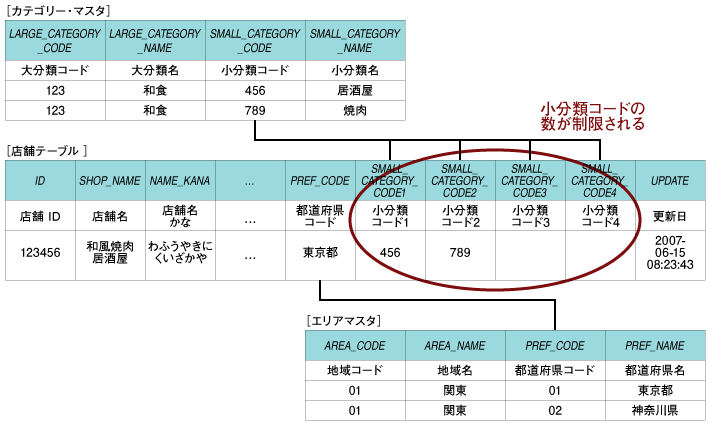 図4:従来のリレーショナルモデルでの設計 (画像をクリックすると別ウィンドウに拡大図を表示します)  図5:pureXMLを使ったデータ設計(ハイブリッド) (画像をクリックすると別ウィンドウに拡大図を表示します) このようにXMLデータベースは機能的にはWeb 2.0型のサービスに対して、従来のRDBMSよりもかなり向いているということがわかると思います。 それではパフォーマンスに関してはどうでしょうか? 2003年頃にXMLデータベースが流行った時期がありましたが、その当時はパフォーマンスが今ひとつだったため、今だにそのときのイメージを持っていらっしゃる方が多いようですが、pureXMLはもうそんなことはありません。スケーラビリティとパフォーマンスが実証されています。 以下のグラフは、店舗を検索するWeb APIを想定してベンチマークを行った結果です。一般的なWeb APIのように「地域」と「カテゴリ」を検索条件としてデータを検索し、結果をXMLで返すというREST型のWeb APIを想定しています。グラフは1秒当たりのPV(ページビュー)を測定したものです。アプリケーションはPHPで作成し、測定にはJMeterを利用して、同時クライアント接続数を100とした条件で測定しています。 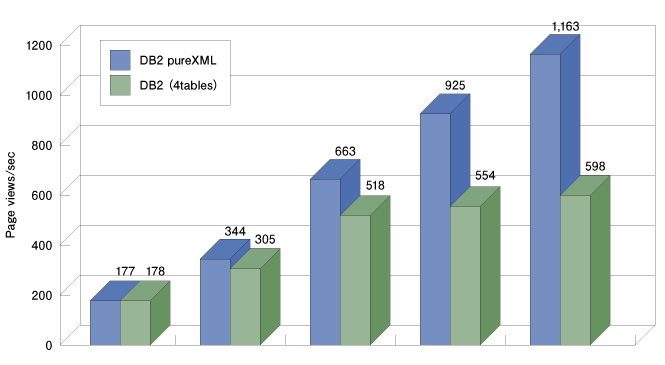 図6:Web 2.0 REST Service CPU Scalability (画像をクリックすると別ウィンドウに拡大図を表示します) 結果を見ると一目瞭然ですが、pureXMLを使った場合でも、RDBMSにも全く引けをとらないどころか、CPUスケーラビリティに関してはRDBMSを大きく上回る結果となっています。RDBMSのスケーラビリティが伸び悩んでいるように見えるのは、テーブルの結合に思ったよりオーバーヘッドがあるからです。テーブルの正規化を崩していけば、オーバーヘッドは少なくなるのですが、前述のように小分類の繰り返しが制限されてしまったり、サービス面で劣ってしまうことになります。 | ||||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||||
| ||||||||||||||
| ||||||||||||||
| ||||||||||||||
-
人気記事ランキング
-
-
連載

