| ||||||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||||||
| 単語インデックスとN-gram | ||||||||||||||||
連載の第1回に、検索の高速化のためのインデックスという仕組みを説明しました。辞書には、読み順インデックスの仕組みはありましたが、全文検索インデックスの仕組みはありませんでした。ところで、身近な全文検索インデックスの例は何でしょうか。そう、本の末尾にある索引です。 索引は、単語とその単語の記載ページが示されています。かつ、単語は読み順に並んでいます。では、索引に載っていない単語を調べたいときはどうするか。これは、索引の仕組みが使えませんから、全ページを探すことになってしまいます。せっかくの索引の仕組みも、中身が漏れてしまえば意味がありません。このように本の索引では、どの単語を索引に登録するかが非常に重要なのです。 また、登録する単語の単位も重要です。例えば、歴史に関する本を想定します。索引には、「鎌倉幕府」「室町幕府」「江戸幕府」が登録されているとします。ここで「幕府」に関する記載ページを調べようとした場合、どうなるでしょうか。索引は、読み順に並んでいますが、「幕府」はありません。索引の「は行」のページは、「か行」「ま行」「あ行」とは離れていますから、今、開いているページには、幕府の文字は見当たらないかもしれません。例え、たまたま目に入ったとしても、網羅性の保証はありません。このような場合、索引は効果がないことがわかります。 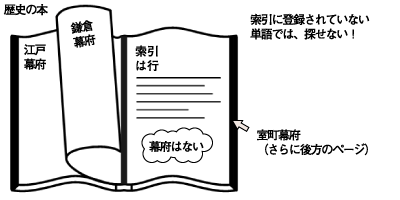 図5:本の索引 システムにおける全文検索も書籍の索引と同様に、全文検索インデックスに「何」を、「どのような単位」で登録するかが重要な意味を持ちます。全文検索インデックスに登録する単位をトークンといいます。トークンの作成方法の違いにより、全文検索インデックスは2種類に分類されます。 | ||||||||||||||||
| 単語インデックス | ||||||||||||||||
単語インデックスは、言語で意味を持つ最小単位(=形態素)に分割したものをトークンとします。日本語は西洋言語と異なり単語をスペースで区切る習慣がありません。そのため、自然文書から形態素解析の技術を用いて単語に分割し、これをトークンとして全文検索インデックスに登録します。形態素解析を行う際には、リファレンスとなる単語辞書が必要となります。また、トークンの分割精度は使用する単語辞書の精度に依存します。 単語インデックスの方式では、1つ1つのトークンが言語として意味を持っていますので、適合率が高くなります。しかし、本の索引と同様にトークンの区切り方のずれによる検索漏れの可能性もあります。 | ||||||||||||||||
| N-gram | ||||||||||||||||
N-gramとは意味のまとまりとは無関係に、一定のn文字単位に分割したものをトークンとします。nが1であればmono-gram、nが2であればbi-gram、nが3であればtri-gramと呼ばれます。例えば「日本語の解析」という文字列をbi-gramで分解すると、「日本」「本語」「語の」「の解」「解析」というトークンに分解されます。これらを全文検索インデックスに登録すると、単語辞書を用意する必要がなく、検索の漏れも発生しません。従って再現率が高くなります。 しかし、京都で東京都がヒットするなど、適合率は低下します。 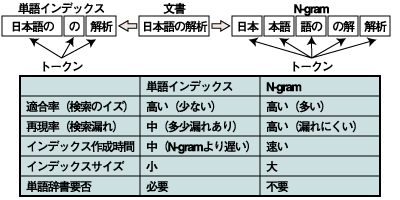 図6:単語インデックスとN-gram 全文検索機能の導入では、候補となるソフトウェアがどのインデックス方式をサポートしているか確認することが大切です。また、導入するシステムの特性から、適用率を高くするべきか、再現率を高くするべきかを決め、適切なソフトウェアを選択する必要があります。 一般的に、インターネットでの検索や図書館のデータのように非常に件数が多いデータの場合は単語インデックスを採用し、ノイズを削減することを優先させます。ノイズが多いと欲しい文書にたどり着けない可能性があるからです。 逆に特許調査など、必要な文書の検索漏れが大きな影響を与える場合には、N-gramを採用して検索漏れを防止することを優先します。また、ブログ検索のように新しい言葉が続々と生まれるような場合は、N-gramが適切です。ブログでは単語辞書にない単語がどんどん登場するため、単語辞書のメンテナンスが追い付かないからです。 | ||||||||||||||||
| 再現率向上の仕組み〜シソーラス検索〜 | ||||||||||||||||
全文検索における再現率向上のためには、同じ意味の別の言い方も含めて検索する必要がある場合があります。例えば「首相」で検索して、「総理大臣」を含む文書を検索する場合です。このような検索には、シソーラスといわれる単語の意味関係で分類した辞書を用いることで実現します。これは単語と単語の意味関係をたどって検索する仕組みといえます。 | ||||||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
-
人気記事ランキング
-
-
連載

